A State of Refactoring
I was recently working on a feature with requirements and constraints that can be boiled down to:
-
Listen for filesystem change events and initiate an asynchronous worker process. The simplified watcher API:
var watcher = require('./watcher'); watcher.on('change', function () { // Do something useful });
-
The worker process cannot handle concurrency, so ensure only one worker is running at a time. The simplified worker API:
var worker = require('./worker'); worker.run(function (err) { // Invoked when the worker is done });
-
If a change event is emitted while the process is running, mark the output as stale and re-run the process when it finishes.
-
While stale, any additional change events can be ignored, and the process only needs to be re-run once.
-
In JavaScript.
Branching Out
As I was exploring the problem space, my first cut at a solution that passed my tests looked a lot like:
var worker = require('./worker')
, watcher = require('./watcher')
, working = false
, stale = false;
watcher.on('change', function () {
function handler(err) {
if (err) {
console.error(err.stack);
return process.exit(1);
}
if (stale) {
stale = false;
worker.run(handler);
}
else {
working = false;
}
}
if (!working) {
working = true;
worker.run(handler);
}
else { // working
stale = true;
}
});
This solution uses two variables at module scope (working and stale) to keep track of system state. Change events and worker callbacks branch on the current state to determine the necessary state modifications and worker strategy. The worker callback needs to reference itself to handle the stale case.
This code works, but it’s not very easy to read. There is a lot of bookkeeping around the two state variables. A reader would be very hardpressed to infer the problem requirements from the code itself. In other words, it’s the kind of code that is just asking for bugs the next time an unfamiliar developer dives into it.
State, Meet Machine
While attempting to refactor my initial implementation into something cleaner and more maintainable, I noted that I was effectively building a machine with three states (ready, working, stale) that responds to two events (change, done).
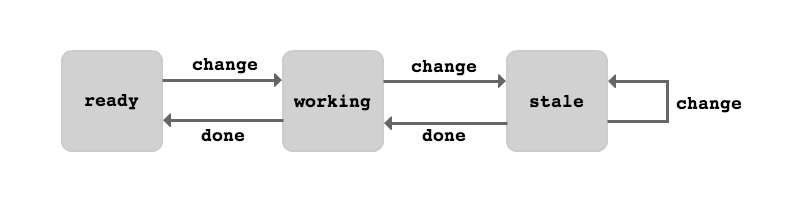
The machine’s transitions can be described with a simple JavaScript object:
{
ready: {
change: 'working'
}
, working: {
change: 'stale'
, done: 'ready'
}
, stale: {
change: 'stale'
, done: 'working'
}
}
Given this declarative state machine definition, all I needed was a way to proxy watcher change events to the machine and observe when the machine entered the working state. This yields a considerably more straightforward solution:
var statem = require('statem')
, worker = require('./worker')
, watcher = require('./watcher')
, machine;
machine = statem.machine({
initial: 'ready'
, states: {
ready: {
change: 'working'
}
, working: {
change: 'stale'
, done: 'ready'
}
, stale: {
change: 'stale'
, done: 'working'
}
}
});
machine.onEnter('working', function () {
worker.run(function (err) {
if (err) {
console.error(err.stack);
return process.exit(1);
}
machine.send('done');
});
});
watcher.on('change', function () {
machine.send('change');
});
One Little Problem
➜ ~ npm info statem npm http GET https://registry.npmjs.org/statem npm http 404 https://registry.npmjs.org/statem npm ERR! 404 'statem' is not in the npm registry. npm ERR! 404 You should bug the author to publish it
I often write code to APIs that don’t exist, if only to fully understand what the perfect API looks like from the consumer perspective. There is a limit to this, but I definitely don’t like pushing complexity to the consumer when it can be avoided.
In this case, I found myself staring at a wall of JavaScript state machines, none of which really provided the semantics and simplicity I was looking for. Pragmatism won the day, and I ended up shipping the feature with javascript-state-machine, but I eventually found time to poke at the problem a bit myself.
I now have a mostly complete implementation of statem built on top of Node’s EventEmitter. I haven’t published it yet, mostly because I need to explore how I want the libary to behave in error cases (invalid states, invalid transitions, etc.). I’m also a bit wary of adding to the proliferation of state machine options without a compelling differentiator. Though it seems doing so is The Node Way™.
In the meantime, consider it a work in progress.